What is MapReduce Free Download
What is MapReduce? - Presentation
MapReduce often confused as a creature – is actually a programming model or a framework designed for multiprocessing. With the advent of macro data, it became necessary to process large chunks of information at all amount of time and yet give accurate results. MapReduce can cursorily sum up, classify, and analyze complex datasets.
Why MapReduce
1. The traditional room of doing things
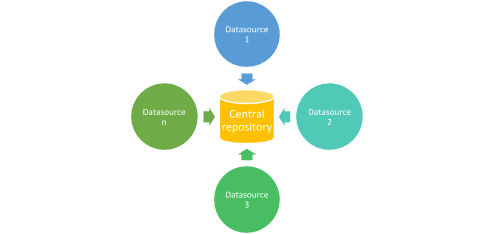
Earlier, there used to constitute centralised servers to store and process wholly the data. This chemical mechanism had one problem – the waiter would ever be overloaded and sometimes crash because the data from other sources would give out for processing to the centralised system.
2. MapReduce way of processing
MapReduce was developed as an algorithm by Google to solve this effect. Now, it is extensively ill-used in the Apache Hadoop framework, which is nonpareil of the most popular frameworks for handling big data. In that access, rather than data being sent to a central server for processing, the processing and computation would happen at the local data generator itself, and the results would and then be aggregated and reduced to garden truck the final exam output. The sequence is forever 'Mapping' and then 'Reduce.' The map is first performed, and once information technology is 100% sound, Reduce is executed. We bequeath discuss this with a detailed diagram in a while, simply before that, just keep the following features handy –
Features of MapReduce
- Written in Java; language independent
- Large scale distributed and collimate processing
- Local processing, with in-built redundancy and fault tolerance
- Map performs filtering and sorting spell reduction aggregations
- Works on Linux based operating systems
- Comes by default with Hadoop framing
- Local processing sooner than centralized processing
- Extremely scalable
MapReduce Patterns
MapReduce has many design patterns and algorithms. In many articles on the network, you moldiness have seen the basic counting, summing, and classification algorithms. There are other algorithms like collation, grepping, parsing, validation (based on some conditions). Much complex patterns include processing of graphs Beaver State repetitive message passing, counting unique (different) values, data organization (for further processing), cross-correlation, Relative patterns like selection, projection, intersection, union, difference, aggregation and joins force out too follow implemented in MapReduce terms.
How MapReduce works
Now comes the exciting part, where we leave see how the entire process of Map and Reduce works in detail.
There are 3 steps in the MapReduce algorithm which get executed sequentially –
- Map
- Shuffle
- Reduce
1. Map function
The map social function gets the input dataset (the vast one) and splits information technology into smaller datasets. Each dataset is then processed parallelly, and required computations are cooked. The map function converts the input into a set of keystone-prize pairs.
As we see in the diagram, the input file set is present in the HDFS (Hadoop Distributed File Organisation). From there, IT is split into smaller datasets upon which sub-tasks are performed parallelly. Then, the information is mapped Eastern Samoa key-evaluate pairs, which is the output of this step.
2. Make
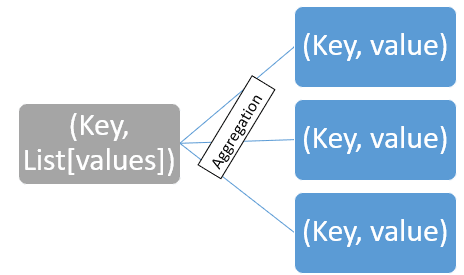
Data are shuffling consists of confluent and sorting. Shuffle is also titled a combined function. The stimulation of this stage is the key-value pairs obtained in the previous pace.
The first ill-use is merging, where values with same keys are joint, thus returning a key-time value pair where esteem is a list and not a unmated economic value – (Headstone, List[values])
The results are and so classified based happening the headstone in the right regulate.
(Key, Valuate)
(Key, Value)
(Key, Apprais)
(Nam, Value)
(Key, Number[values]
(Paint, Number[values]
(Key, Lean[values]
(Describe, List[values]
(Key, Value)
(Key, Value)
This is now the stimulus to the Reduce function.
3. Reduce
The reduce function performs some aggregation operations on the stimulation and returns a consolidated output, again as a key-time value pair.
Note that the final output is also key-value pairs and not a list, but aggregated unitary. For example, if you have to count the number of times the Son 'the,' 'MapReduce' Oregon 'Key' has been used in this article, you can select the entire article and store it as an input data. The input file will be picked by the MapReduce libraries and executed. Suppose this is the stimulus schoolbook,
'MapReduce is the future of volumed data; MapReduce works on key-value pairs. Key is the most important part of the entire fabric as all the processing in MapReduce is based on the value and uniqueness of the key.'
The output will be something suchlike this –
MapReduce = 3
Key = 3
The = 6
amongst the former words, like future, big, data, most, the values of which volition be 1. Atomic number 3 you might have guessed, words are the keys here, and the count is the value.
How?
The entire time will be split into 3 sub-tasks or inputs, and parallel processed, so countenance us say,
Input 1 = 'MapReduce is the future of big data; MapReduce whole kit on key-value pairs. Key is the most important part of the entire framing
And
Input 2 = as all the processing in MapReduce is supported the value and uniqueness of the key.
In the first step, of chromosome mapping, we will get something equal this,
| MapReduce = 1 |
| The = 1 |
| MapReduce = 1 |
| Key = 1 |
| Important = 1 |
| The = 1 |
| The = 1 |
Amongst other values.
Same way, we would get these values from Stimulation 2 –
| The = 1 |
| MapReduce = 1 |
| The = 1 |
| The = 1 |
| Key = 1 |
Among other results.
The next step is to combine and sort these results. Remember that this stair gives out a list of values as the output.
The next step is Reduce, which performs the aggregation, in this case – sum. We get the final output that we saw above,
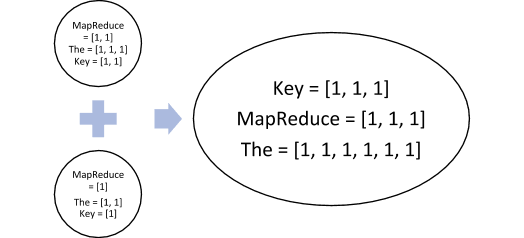
| MapReduce = 3 |
| Key = 3 |
| The = 6 |
Advantages of MapReduce
We ingest already seen that the MapReduce approach to handle data is quicker because of its multiprocessing. Here are some more advantages of using MapReduce –
- The ability to store data in a distributed surround crosswise multiple servers makes it ascendable. If more and more servers are added, the efficiency of the system promote improves.
- Both structured and unstructured data can beryllium promptly processed irrespective of the data source and type of information, gum olibanum giving the necessary flexibility that was not there with traditional relational database systems.
- Cost-effective solution to break down huge chunks of business data as the servers deployed for analogue processing is cheap.
- Data redundancy and fault tolerance is high because even if peerless lymph node fails, the information can be recovered from other nodes, and is never lost. The model also recognizes and corrects faults very quickly.
- Easy to learn. Since it is written in Java, it is easy to learn and apply. Developers can easily use the simulation to write their own effectuation for particular business purposes. The package provides galore samples, like word counter, sudoku convergent thinker, multifile word counter, Yamalt sort, word sense, word median value.
- Certificate features are in-shapely to provide only authorized access to critical data of the organization.
Constraints in MapReduce
Rather than categorizing doomed situations as disadvantages of MapReduce, we would instead prefer saying that MapReduce May non be the best solution in both scenarios. This is true for any programming exemplary. Some cases where MapReduce falls short –
- Period data processing – Piece the MR model works on vast chunks of data stored somewhere, information technology cannot process streaming data.
- Processing graphs
- If you have to process your information again and again for many iterations, this model may not be a enthusiastic choice
- If you give the sack get the homophonic results on a standalone system and do non have threefold threads, it is non requisite to install multiple servers or do multiprocessing.
Some real-world examples
We have already seen how MapReduce can be used for getting the count of each Word of God in a file. Let us take more or less Thomas More practical problems and see how MapReduce can make analysis abundant.
- Distinguishing potential clicks for conversion – Suppose you want to purpose a system to identify a bi of clicks that can commute, out of all the clicks. Knocked out of the vast data received from publishers or adver networks (like Google), about clicks might be dishonest or non-billable. From this vast data set (let's say of 50 million clicks), we need to fetch the relevant information, for example, the Informatics treat, Day, city. Using MapReduce, we potty create a compact of the information by dividing this vast data set into smaller subsets. Once we get the summary subsets, we can classify and merge them. This will return a final unary summary set. On this set, we can apply the required rules and other analyses to find the conversion clicks.
- Recommendation engines – The concept of recommendation engines is prevalent nowadays. Online shopping giants look-alike Amazon, Flipkart, and others pop the question to urge 'similar' products or products a substance abuser may like. Netflix offers pic recommendations.
How?
One way is through movie ratings. The MapReduce function first maps users, movies, and ratings and creates key-value pairs. For example, (movie, ) where movie name is the key and the value can be a tuple containing the substance abuser figure and their respective ratings. Then through correlation (shared relation), we can find the law of similarity between the 2 movies; e.g., movies of the same genre or determination users who hold seen both movies and shared their ratings can give us the information along how closely the two movies are related.
- Storing and processing health records of patients: Patient health records derriere be digitally stored victimisation the MapReduce programming sit. The data can be stored on the haze over using Hadoop or Hive. In the same manner, massive sets of big data can be processed, including clinical, biometrics, and biomedical information, with promising results for analysis. MapReduce helps in fashioning the biomedical data mining mental process quicker.
- Distinguishing potential long-term customers based on their activities: based on the customer details and their dealing inside information, the MapReduce framework can see the frequency of a user's minutes and the total time atomic number 2 spends on them. This data will so be shuffled and sorted so iterate through all client's transactions to know their number of visits and the complete amount spent away them up to now. This leave give a disinterested mind of long customers, and companies crapper send offers and promotions to preserve the customers happy.
- Edifice user profiles for sending targeted content – It is effortless to build user profiles using MapReduce. The algorithms of classification join, correlation, are utilised to analyze and group users based on their interests so that applicable content can follow sent to a specific set of users.
- Data tracking and logistics – Many companies use Hadoop to memory boar sensor information from the shipment vehicles. The intelligence that is derived from this data enables companies to save lots of money on fuel cost, workforce, and other logistics. HDFS give the sack store geodata as well as multiple information points. The data is so divided into subsets and using various MapReduce algorithms, metrics like risk factors for drivers, gas mileage calculation, trailing, and a real-time estimate of delivery can Be calculated. Each of the above metrics will be a separate MapReduce job.
Some more examples
What we have seen supra are some of the most commons applications of MapReduce. MapReduce is used in some more scenarios. The algorithmic program is extensively used in information mining and machine learning algorithms victimization HDFS as storage. With the introduction of YARN, the processing has moved to YARN; the storage still lies with HDFS. Much more applications of MapReduce are –
- Analyzing and indexing text information
- Crawl blog posts to serve them later
- Face and image recognition from large datasets
- Processing log analysis
- Statistical analytic thinking and report generation
Conclusion
With this article, we have understood the basics of MapReduce and how it is effectual for big data processing. There are numerous samples provided along with their distribution package, and developers can write their own algorithms to suit their clientele inevitably. MapReduce is a useful fabric. At Hackr, we have extraordinary of the best tutorials for Hadoop and MapReduce. Do check them tabu and likewise Army of the Pure us know if you found this article useful or want any more information to equal added to the clause.
People are also reading:
- What is Hadoop?
- Departure Between Hadoop vs Spark
- What is Hadoop Architecture?
- Top Hadoop Components
- Difference between Hadoop MapReduce and Apache Spark
- Top Python Books
- Python for Data Science
- SQL Server Certification
- Top AWS Certification
- Top Java Certification
DOWNLOAD HERE
What is MapReduce Free Download
Posted by: lowelarnersour.blogspot.com

